Dataset
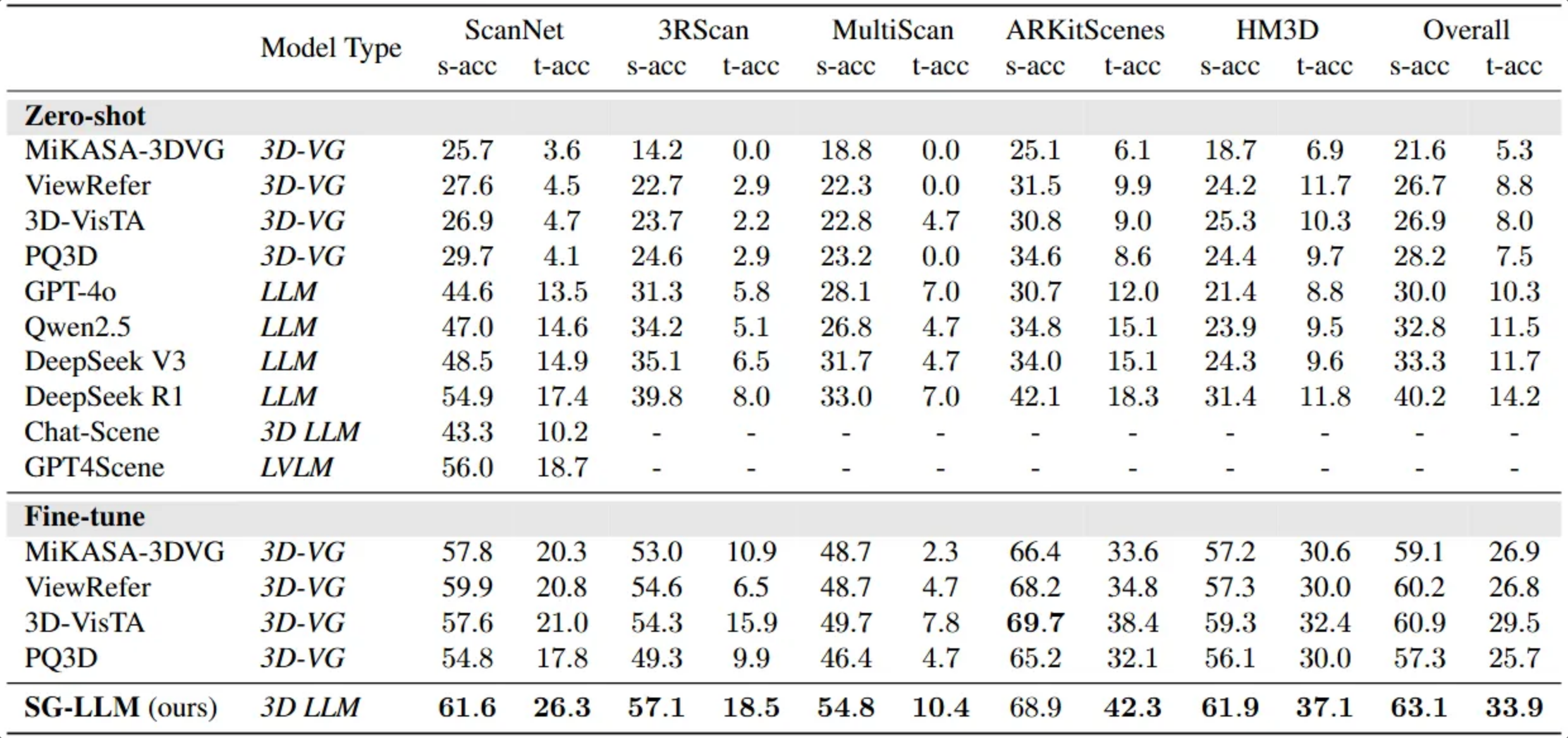
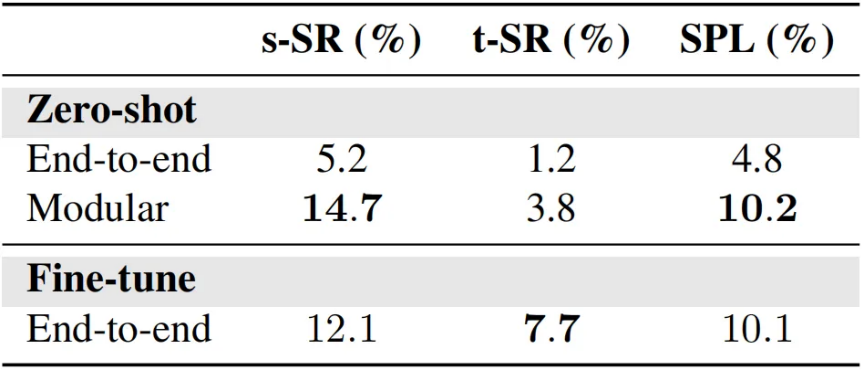
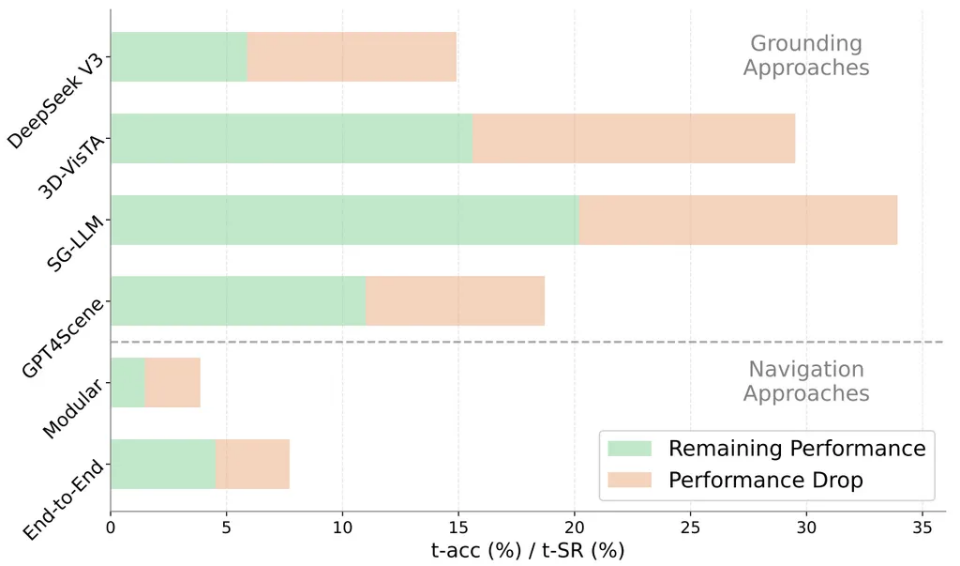
SG3D contains 3D scenes curated from diverse existing datasets of real environments. Harnessing the power of 3D scene graphs and GPT-4, we introduce an automated pipeline to generate tasks. Post-generation, we manually verify the test set data to ensure data quality.